Новые эксперименты на кластере
Для исправления недостатков предыдущего эксперимента было решено переписать сервер на языке си, а так же встроить синхронизацию в решатель, чтобы избежать накладных расходов на передачу управления от решателя к скрипту синхронизации и обратно. Этот эксперимент проводился на кластере ОмГТУ, для расчётов было задействовано 9 и 16 ядер, а так же управляющий компьютер в качестве компьютера клиента, т.е. на нём были запущены сервер и вычислитель с одной подзадачей.
Ещё одной особенностью данного эксперимента является то, что на одном кластере эмулировалось сразу два кластера, то есть на кластере было запущенно по 2 группы решателей, которые между собой обменивались данным посредством сервера, а не напрямую через MPI. Схематично это можно увидеть на рис. 1 и рис. 2 . Результаты этого эксперимента можно увидеть в таблице 1.
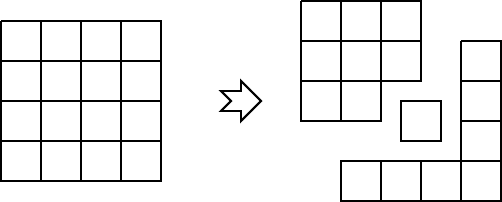
Рис. 1. Разделение 16 подзадач на два кластера и компьютер клиента
Таблица 1. Запуск эксперимента на кластере и компьютере
|
Размер задачи |
Количество ядер |
Период обмена |
Время полное, с |
Время вычислений, с |
Время синхронизации, с |
Кол-во итераций |
|
1000х1000 |
1 |
— |
644.292 |
644.292 |
— |
78162 |
|
1000х1000 |
9 |
1500 |
13372.576 |
6188.867 |
7183.617 |
7372500 |
|
1000х1000 |
16 |
250 |
14041.019 |
983.865 |
13017.801 |
1616250 |
|
2000х2000 |
1 |
— |
7053.525 |
7053.525 |
— |
201641 |
|
2000х2000 |
9 |
750 |
35509.953 |
26569.079 |
8900.073 |
5706000 |
|
2000х2000 |
16 |
250 |
21519.828 |
4504.495 |
16976.26 |
2314000 |
|
3000х3000 |
9 |
750 |
86284.481 |
73300.486 |
12980.843 |
7915500 |
|
3000х3000 |
16 |
250 |
37334.286 |
15393.569 |
21900.226 |
3614750 |
|
4000х4000 |
1 |
— |
>86400 |
>86400 |
— |
— |
|
4000х4000 |
9 |
1500 |
>86400 |
— |
— |
— |
|
4000х4000 |
16 |
250 |
67954.636 |
41078.507 |
26849.413 |
3628250 |
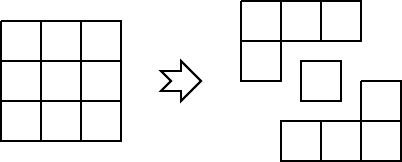
Рис. 2. Разделение 9 подзадач на два кластера и компьютер клиента
Результаты экспериментов
Из результатов последнего эксперимента видно, что время расчётов существенно возросло. Это связано с тем, что теперь и граничные значения участвуют при измерении невязки. А значит, для завершения вычислений необходимо, чтобы невязка была меньше ε и для граничных условий, которые изменяются 1 раз в период обмена итераций, что тоже не совсем верно. Время синхронизации хоть и уменьшилось, но всё ещё является существенным фактором, тормозящим вычисления. Данные результаты так же были экстраполированы для того чтобы оценить возможный выигрыш в производительности и применимость схемы в целом. График можно увидеть на рис. 3.
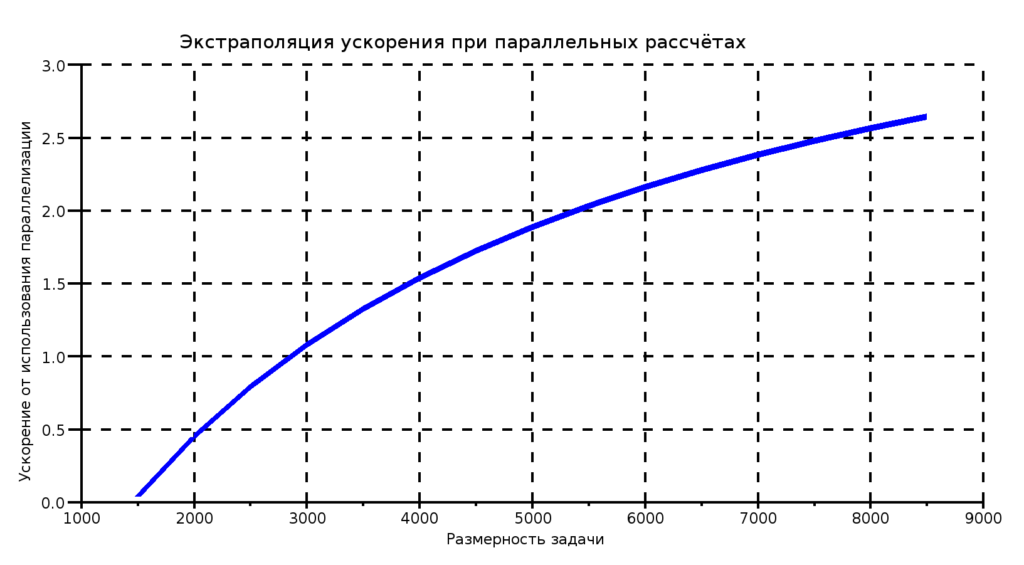
Рис. 3. Экстраполяция ускорения при параллельных расчётах
Из графика видно, что, как и в предыдущем эксперименте, данная схема предпочтительна для матриц больших размерностей. И хоть какой-то выигрыш будет получен при размере 3000х3000 и более. Можно выразить результат двумя словами: «не зря!». Не зря переписывал программу, лучше стало. Однако, ещё есть над чем работать.