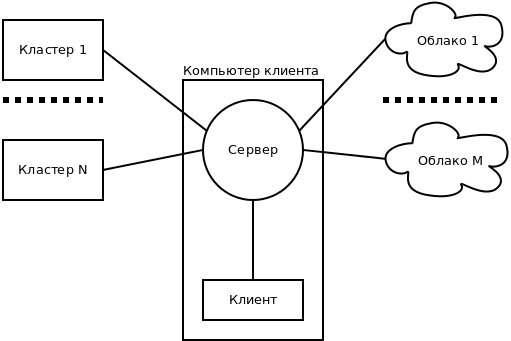
Клиент-серверная архитектура
Здесь для читателя будет предложена клиент-серверная архитектура, которую я использовал для реализации вычислений. Ранее уже объяснялась необходимость использования серверного приложения для синхронизации вычислений. Конечно, если бы информация не была такой важной, то можно было бы просто распараллелить её обработку и позже получить результаты. Однако, из-за того, что это не так и часть информации никогда не попадёт в ЦОД и нужен сервер. Клиент-серверная архитектура оправдывает себя и при рассылке задач на вычислительные узлы и их сбор по завершению решения. К сожалению, это некоторый велосипед, повторно реализующий функции MPI.
Описание клиент-серверной архитектуры
По сути, существует два вида решателей, это решатель для запуска без MPI и решатель для запуска с MPI. Все три программы реализованы для POSIX-совместимых операционных систем. Каждый решатель реализует алгоритм конкретной подзадачи, в данном случае метод последовательной верхней итерации, а так же процедуру синхронизации с сервером. Решатель с MPI так же содержит код для обмена данных между другими решателями кластера, с помощью вызова функций MPI.
Теперь перейдём к серверу. Для большей скорости обмена была выбрана многопоточная архитектура сервера. Существует две общие области для всех потоков, это массив максимальных значений невязки, а так же матрица состояния файлов. Массив максимальных значений невязки, как видно из названия, содержит максимальные значения невязок для каждого решателя, а матрица состояния файлов представляет собой двумерный массив, каждый элемент которого отвечает за статус файла между решателем с номером строки этого элемента и решателем с номером столбца этого элемента.
Всего существует два статуса это «принят» и «отправлен». Изначально вся матрица заполняется статусом «отправлен». В процессе выполнения некоторые элементы изменяются на «принят». Данная матрица нужна для того, чтобы, во-первых, знать есть ли такой файл на сервере, а во-вторых, каждый решатель получал актуальные данные и не совершал расчёты с данными полученными на предыдущих итерациях. Этот способ имеет свои минусы, а именно решатели могут достаточно долгое время простаивать из-за того, что какой-либо один решатель не предоставляет свои файлы «перехлёста». Однако, в этой ситуации ничего не поделать. Смысла обрабатывать данные с неверными граничными условиями нет.
В качестве примитива синхронизации для общих областей использовались мьютексы (mutex). Каждый поток блокировал на чтение или запись массив с максимальными значениями невязки или матрицу состояния файлов. Для реализации понадобилось всего 2 мьютекса, а не мьютекс для каждого файла. Кроме того не было необходимости блокировать матрицу состояний на всё время передачи файлов, так как на запрос на файл может прислать только один из двух решателей, а значит достаточно только узнать состояние, а затем либо удовлетворить запрос решателя на закачку или скачивание файла, либо отказать.
Итоги
Напоследок хотелось бы добавить, что подобная архитектура позволяет объединять для вычислений, как некоторое количество обычных компьютеров, так и несколько кластеров и, даже, несколько кластеров и компьютеров одновременно. Это можно увидеть на следующем рисунке.