Разделение секрета
Разделение секрета это тема моей последней курсовой, дипломной работы и с этой темой я поступил в аспирантуру. Обычно под схемой разделения секрета предполагается, что существует некая важная информация — секрет, которую необходимо разделить между участниками так, чтобы каждый из участников обмена получил равную долю секрета. Заранее заданные коалиции участников (разрешённые коалиции) могли бы восстановить секрет или пройти авторизацию на основе своих частей, а другие коалиции (неразрешённые коалиции) не могли бы пройти авторизацию и узнать какую-либо дополнительную информацию о секрете, кроме уже известной априорной информации.
Такие схемы разделения секрета называют совершенными. Если размер доли секрета (тени) не больше размера самого секрета, то такие схемы разделения секрета считают идеальными. Если разрешёнными коалициями являются коалиции, состоящие из n и более пользователей, а коалиции строго меньшего размера являются неразрешёнными, то такие схемы разделения секрета называют пороговыми.
Классические схемы
В настоящее время существует множество схем разделения секрета. Самые известные из них это:
-
Схема Шамира — схема разделения секрета, основанная на интерполяционных полиномах Лагранжа;
-
Схема Блэкли — схема разделения секрета, основанная на использовании точек многомерного пространства;
-
Схема Карнин-Грин-Хеллмана — схема разделения секрета, основанная на скалярном произведении;
-
Схема Асмута-Блума — схема разделения секрета, основанная на использовании простых чисел.
Разделение секрета в центрах обработки данных
Но разделение какой-либо малой ключевой информации (вроде pin-кода или пароля) между группой участников не единственный способ применения схем разделения секрета. Они так же могут использоваться и для хранения информации, её передаче и обработке. Поэтому кажется возможным применить аналогичную идею и при передаче вычислений в ЦОД. Большая часть данных, которая не несёт информации об объекте, будет передана для вычислений в ЦОД по открытому каналу связи, тогда как меньшая часть данных, несущая основную информацию об объекте, будет обрабатываться на компьютере клиента.
Благодаря этому клиент может передать часть своих данных для расчёта в ЦОД, не опасаясь за компрометацию всей задачи и объекта, поскольку расчёт наиболее важных данных будет произведён на машине клиента. Падение производительности из-за этих действий будет несущественным, так как размер доли секрета рассчитываемой на машине клиента мал по сравнению с долями, передаваемыми в ЦОД.
Примеры задач
Рассмотрим тело, находящееся в электростатическом плоскопараллельном и осесимметричном поле (поле многопроводных систем: кабельных и воздушных линий и коридоров линий), в области без зарядов. При описании этого процесса воспользуемся уравнением Лапласа, которое в данном примере описывает потенциал электростатического поля — в области, не содержащей зарядов. Так же, это уравнение используется при описании потенциала сил тяготения в области, не содержащей тяготеющих масс, температуры при стационарных процессах и т. д.
На рис. 1 изображено такое тело, находящееся в электростатическом поле, в области без зарядов. Как видно из рисунка объект занимает лишь малую область в центре, тогда как остальное пространство пустует. Поэтому обработку пустых пространств целесообразно передать в ЦОД, так как эти области не несут информации об объекте, тогда как область 0 необходимо обрабатывать на машине клиента, поскольку именно в ней закодирован объект.
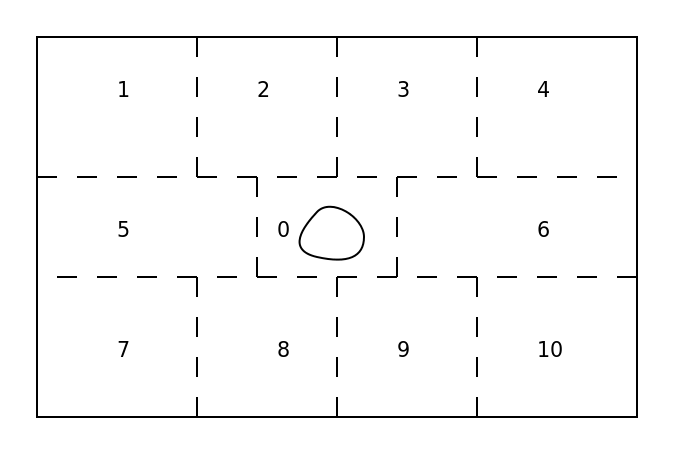
Рис. 1. Разделение области для расчётов. Область 0 для обработки на машине клиента, области 1-10 для обработки в ЦОД
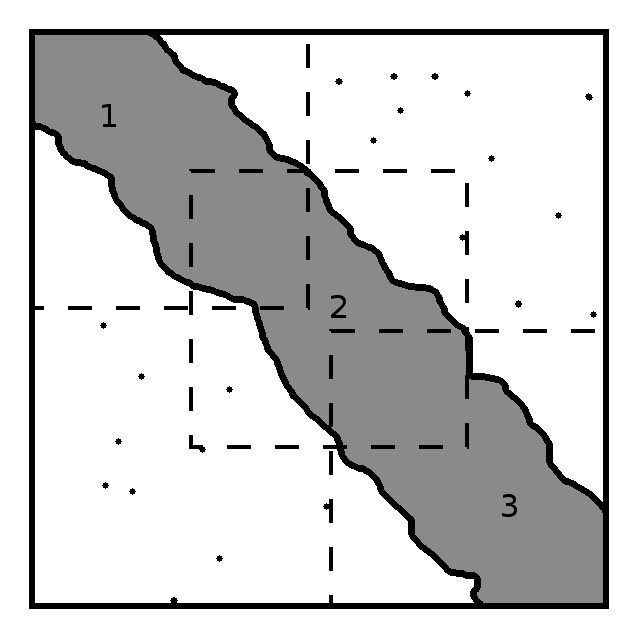
Рис. 2. Разделение задачи поиска максимальной клики.
Разделение по данным не единственный способ применения данной схемы. Так же возможно разделение по операциям, т.е. какие-то громоздкие подготовительные вычисления выполняются в ЦОД или в нескольких ЦОД. А на последнем этапе результаты вычислений попадают к клиенту, после чего на машине клиента производят завершительные вычисления.
Примером такой задачи может быть задача о нахождении максимальной клики в квазиленточном графе, которая изображена на рис. 2. В данном случае граф, а точнее его компьютерное представление — матрица смежности разбивается на подматрицы. После чего каждая подматрица отправляется для вычислений в некоторый ЦОД, причём все ЦОД должны быть разными. Затем результаты вычислений передаются клиенту, на машине которого происходит слияние полученных результатов, либо поиск максимальной клики, среди полученных от ЦОД. Стоит заметить, что этот алгоритм является эвристическим, поскольку он не производит перебора всех возможных клик, оставляя для сравнения лишь несколько максимальных.